Usage
This page explains how to use earthmover: the commands and features available in the tool.
Commands
As a command-line tool, earthmover supports a number of different commands, which are documented below. (Simply running earthmover without specifying a command is equivalent to earthmover run.)
earthmover init
earthmover init creates a simple earthmover project skeleton in the current directory with
- several simple source data files
- an
earthmover.ymlfile - a sample Jinja template
which can be a useful starting point for learning about earthmover or developing a new earthmover project.
earthmover deps
(This command is only needed if your earthmover project depends on packages.) Running earthmover deps will download and install the packages in a packages/ folder. This step must be completed before you can earthmover compile or earthmover run.
earthmover compile
earthmover compile is an optional step that can help validate an earthmover.yml configuration file. Running it renders any Jinja and parameters, then parses the resulting YAML into a data dependency graph. This helps identify any compile-time errors before doing any actual data transformation.
earthmover run
earthmover run compiles an earthmover project and then executes the data dependency graph (in topological order).
Flags that may be used with earthmover run include
-
(If omitted, earthmover looks for-cto specify a YAML configuration fileearthmover.ymlorearthmover.yamlin the current directory.) -
--setto override values specified in the YAML configuration file, for example(earthmover run --set config.tmp_dir path/to/another/dir/ earthmover run --set sources.schools.file './my schools with spaces.csv' earthmover run --set destinations.my_dest.extension ndjson destinations.my_dest.linearize True--setmust be followed by a set of key-value pairs.)
earthmover clean
earthmover clean removes data files created by earthmover (those in config.output_dir), and, if it exists, earthmover_compiled.yml.
earthmover -v
See the currently-installed version of earthmover with
earthmover -h
See a CLI help message with
earthmover -t
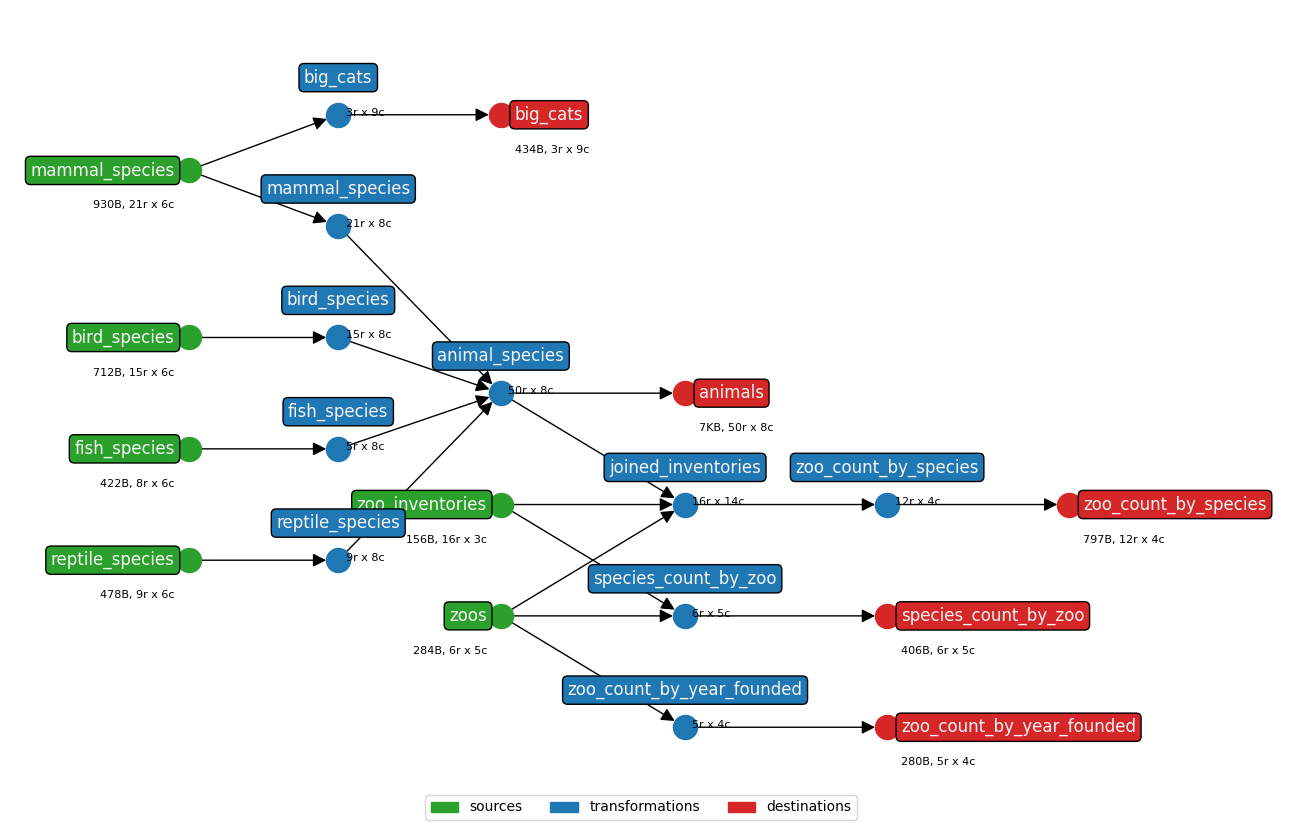
earthmover ships with a test suite covering all transformation operations. It can be run with
earthmover.yaml and toy data in the earthmover/tests/ folder. (The DAG is pictured below.) Rendered earthmover/tests/output/ are then compared against the earthmover/tests/expected/ output; the test passes only if all files match exactly.
Features
State
earthmover can maintain state about past runs, and only re-process subsequent runs if relevant data or configuration has changed — the YAML configuration itself, data files of sources, the map_file(s) of a map_values transformation operation, template file(s) of destinations, or parameter values.
State is tracked by hashing files and parameters; hashes and run timestamps are stored in the file specified by config.state_file. (If that file is not specified, state-tracking is disabled.)
You may choose to force reprocessing of the whole DAG, regardless of whether has changed, using the -f or --force-regenerate command-line flag:
To further avoid computing hashes and not log a run to the state_file, use the -k or --skip-hashing flag:
(This makes a one-time run on large input files faster.)
If earthmover skips running because state has not changed, it returns bash exit code 99 (this was chosen because it signals a "skipped" task in Airflow).
Parameters
earthmover supports parameterization of the YAML configuration via named parameter-value pairs. Example:
Avoid parameters in single quotes under Windows
Because os.path.expandvars() does not expand variables within single quotes in Python under Windows, Windows users should avoid placing parameter references inside single quote strings in their YAML.
Parameter values may be specified via the CLI or as environment variables.
earthmover run -p '{"BASE_DIR":"path/to/my/base/dir"}'
# or
earthmover run --params '{"BASE_DIR":"path/to/my/base/dir"}'
# or
export BASE_DIR=path/to/my/base/dir
earthmover run
Default parameter values can be specified in the YAML configuration's config section, which is particularly useful when developing an earthmover project that is intended to be a package used by other projects.
Jinja in YAML configuration
You may use Jinja in the YAML configuration, which will be parsed at load time. Only the config section may not contain Jinja, except for macros which are made available both at parse-time for Jinja in the YAML configuration and at run-time for Jinja in add_columns or modify_columns transformation operations.
The following example
- loads 9 source files
- adds a column indicating the source file each row came from
- unions the sources together
- if an environment variable or parameter
DO_FILTERING=Trueis passed, filters out certain rows
config:
show_graph: True
parameter_defaults:
DO_FILTERING: "False"
sources:
{% for i in range(1,10) %}
source{{i}}:
file: ./sources/source{{i}}.csv
header_rows: 1
{% endfor %}
transformations:
{% for i in range(1,10) %}
source{{i}}:
source: $sources.source{{i}}
operations:
- operation: add_columns
columns:
source_file: {{i}}
{% endfor %}
stacked:
source: $transformations.source1
operations:
- operation: union
sources:
{% for i in range(2,10) %}
- $transformations.source{{i}}
{% endfor %}
{% if "${DO_FILTERING}"=="True" %}
- operations: filter_rows
query: school_year < 2020
behavior: exclude
{% endif %}
destinations:
final:
source: $transformations.stacked
template: ./json_templates/final.jsont
extension: jsonl
linearize: True
Selectors
Run only portions of the data dependency graph (DAG) by using a selector:
This processes all DAG paths (fromsources through destinations) through any matched nodes.
Optional Sources
If you specify the columns list and optional: True on a file source but leave the file blank, earthmover will create an empty dataframe with the specified columns and pass it through the rest of the DAG. This, combined with the use of parameters to specify a source's file, provides flexibility to include data when it's available but still run when it is missing.
Structured run output
To produce a JSON file with metadata about the run, invoke earthmover with
For example, forexample_projects/09_edfi/, a sample results file would be:
{
"started_at": "2023-06-08T10:21:42.445835",
"working_dir": "/home/someuser/code/repos/earthmover/example_projects/09_edfi",
"config_file": "./earthmover.yaml",
"output_dir": "./output/",
"row_counts": {
"$sources.schools": 6,
"$sources.students_anytown": 1199,
"$sources.students_someville": 1199,
"$destinations.schools": 6,
"$transformations.all_students": 2398,
"$destinations.students": 2398,
"$destinations.studentEducationOrganizationAssociations": 2398,
"$destinations.studentSchoolAssociations": 2398
},
"completed_at": "2023-06-08T10:21:43.118854",
"runtime_sec": 0.673019
}
Project Composition
An earthmover project can import and build upon other earthmover projects by importing them as packages, similar to the concept of dbt packages. When a project uses a package, any elements of the package can be overwritten by the project. This allows you to use majority of the code from a package and specify only the necessary changes in the project.
To install the packages specified in your YAML Configuration, run earthmover deps. Packages will be installed in a nested format in a packages/ directory. Once packages are installed, earthmover can be run as usual. If you make any changes to the packages, run earthmover deps again to install the latest version of the packages.
Composition example
In the example below, an earthmover project projA depends on a package projB. Running earthmover compile on projA/earthmover.yml results in the earthmover.yml files from both projects being combined, with the result shown in projA/earthmover_compiled.yml.
config:
parameter_defaults:
DO_FILTERING: "False"
sources:
source1:
file: ./seeds/source1.csv
header_rows: 1
source2:
file: ./seeds/source2.csv
header_rows: 1
transformations:
trans1:
...
destinations:
dest1:
source: $transformations.trans1
template: ./templates/dest1.jsont
dest2:
source: $sources.source2
template: ./templates/dest2.jsont
config:
show_graph: True
output_dir: ./output
parameter_defaults:
DO_FILTERING: "False"
packages:
pkgB:
local: pkgB
sources:
source1:
file: ./seeds/source1.csv
header_rows: 1
source2:
file: ./packages/pkgB/seeds/source2.csv
header_rows: 1
transformations:
trans1:
...
destinations:
dest1:
source: $transformations.trans1
template: ./templates/dest1.jsont
dest2:
source: $sources.source2
template: ./packages/pkgB/templates/dest2.jsont
Composition considerations
-
The
configsection is not composed from the installed packages, with the exception ofmacrosandparameter_defaults. Specify all desired configuration in the top-level project. -
There is no limit to the number of packages that can be imported and no limit to how deeply they can be nested (i.e. packages can import other packages). However, there are a few things to keep in mind with using multiple packages.
- If multiple packages at the same level (e.g.
projA/packages/pkgBandprojA/packages/pkgC, notprojA/packages/pkgB/packages/pkgC) include same-named nodes, the package specified later in thepackageslist will overwrite. If the node is also specified in the top-level project, its version of the node will overwrite as usual. - A similar limitation exists for macros – a single definition of each macro will be applied everywhere in the project and packages using the same overwrite logic used for the nodes. When you are creating projects that are likely to be used as packages, consider including a namespace in the names of macros with more common operations, such as
assessment123_filter()instead of the more genericfilter().