Design
This page discusses some aspects of earthmover's design.
YAML compilation
earthmover allows Jinja templating expressions in its YAML configuration files. (This is similar to how Ansible Playbooks work.) earthmover parses the YAML in several steps:
- Extract only the
configsection (if any), in order to make available anymacroswhen parsing the rest of the Jinja + YAML. Theconfigsection only may not contain any Jinja (besidesmacros). - Load the entire Jinja + YAML as a string and hydrate all parameter references.
- Parse the hydrated Jinja + YAML string with any
macrosto plain YAML. - Load the plain YAML string as a nested dictionary and begin building and processing the DAG.
Note that due to step (3) above, runtime Jinja expressions (such as column definitions for add_columns or modify_columns operations) should be wrapped with {%raw%}...{%endraw%} to avoid being parsed when the YAML is being loaded.
The parsed YAML is written to a file called earthmover_compiled.yaml in your working directory during a compile command. This file can be used to debug issues related to compile-time Jinja or project composition.
Data dependency graph (DAG)
earthmover models the sources → transformations → destinations data flow as a directed acyclic graph (DAG). earthmover will raise an error if your YAML configuration is not a valid DAG (if, for example, it contains a cycle).
Each component of the DAG is run separately.
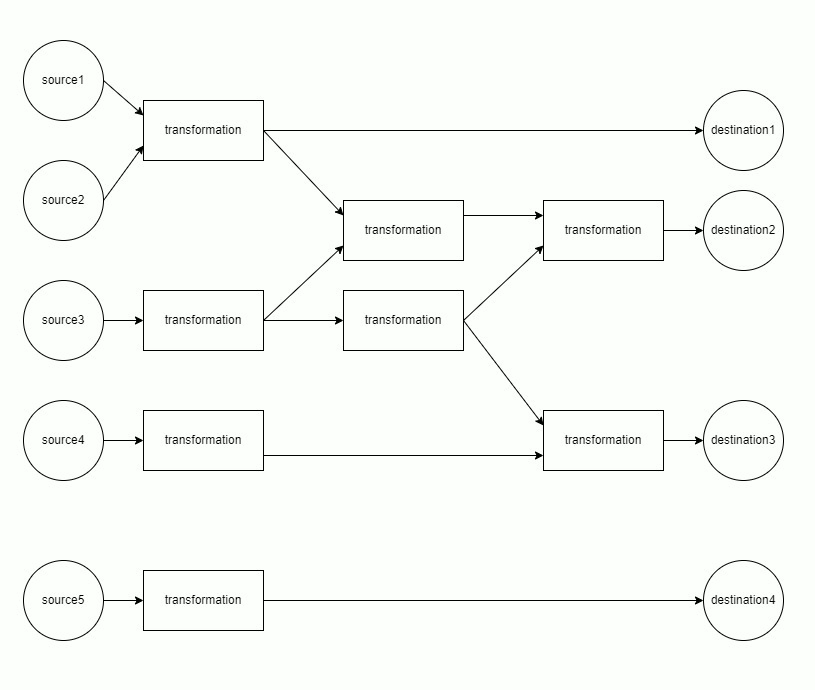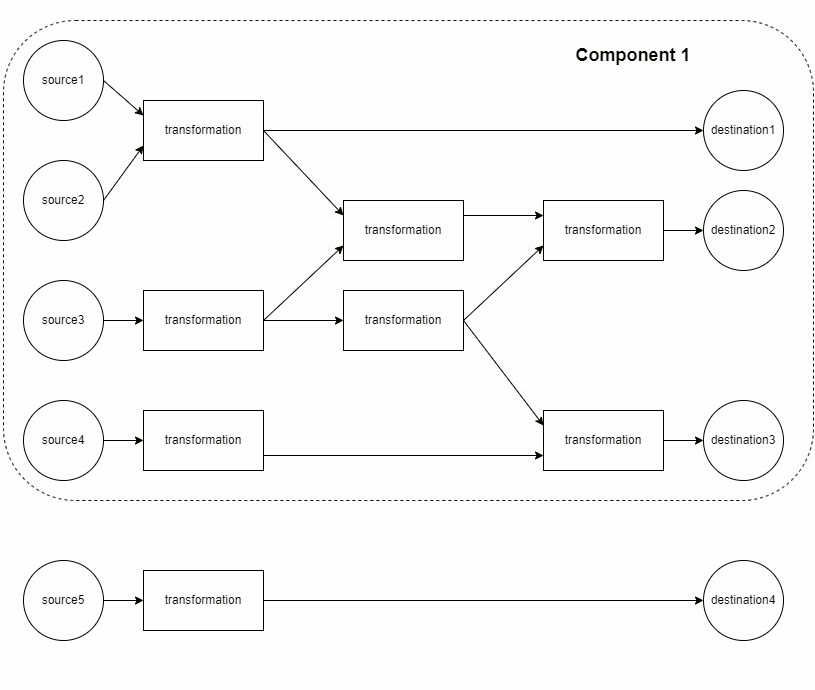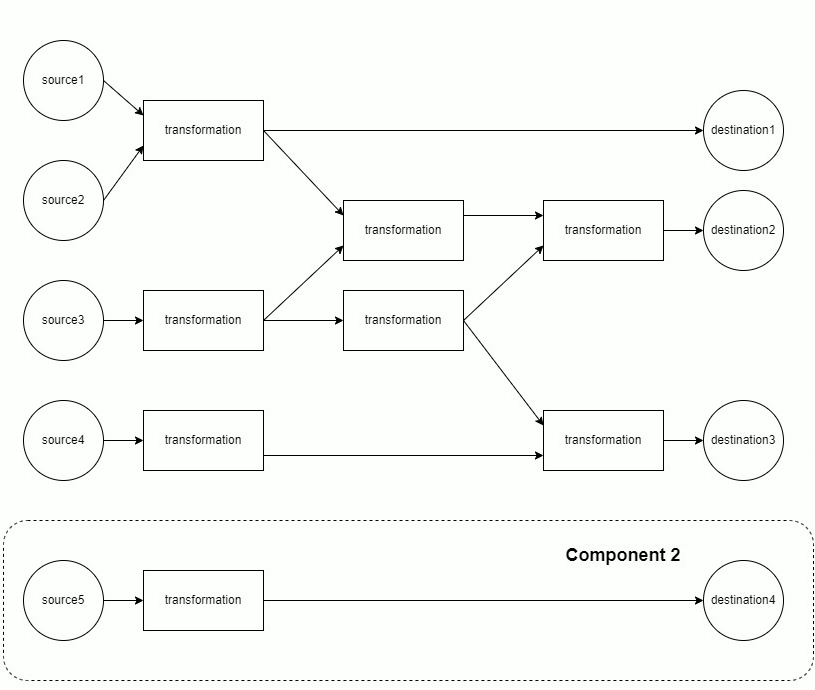
Each component is materialized in topological order. This minimizes memory usage, as only the data from the current and previous layer must be retained in memory.
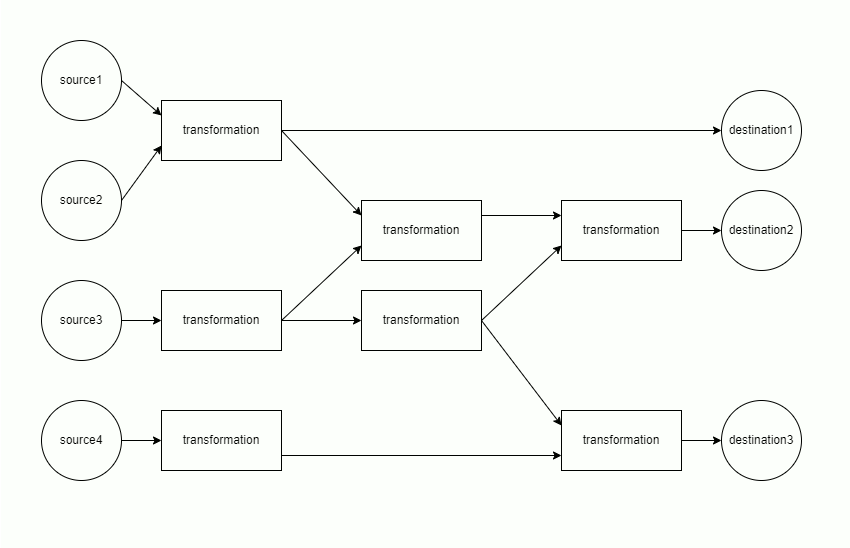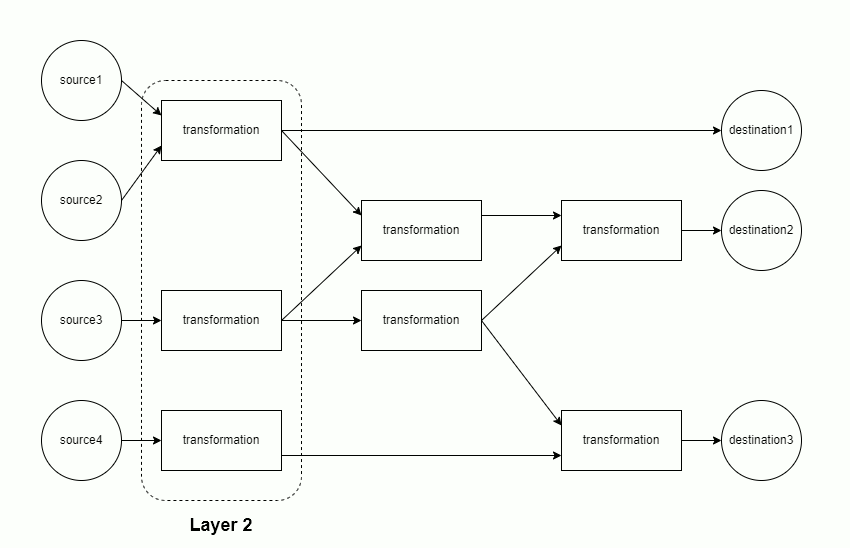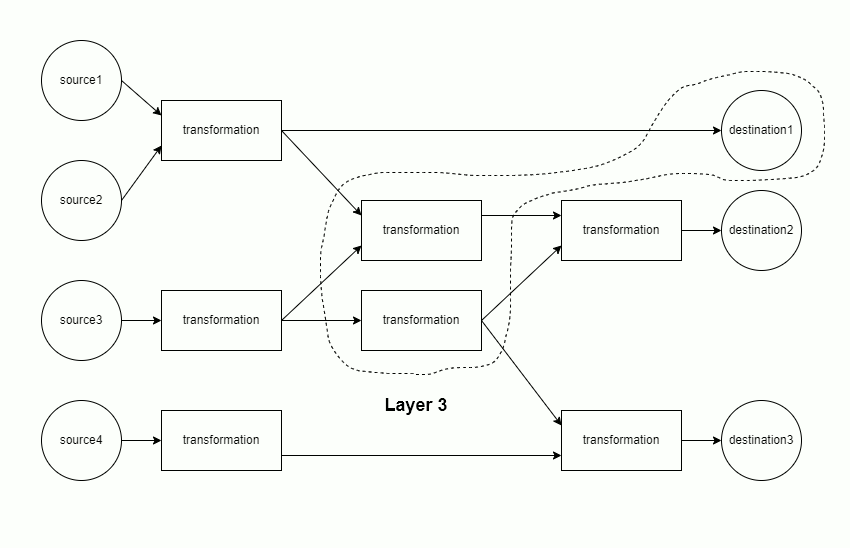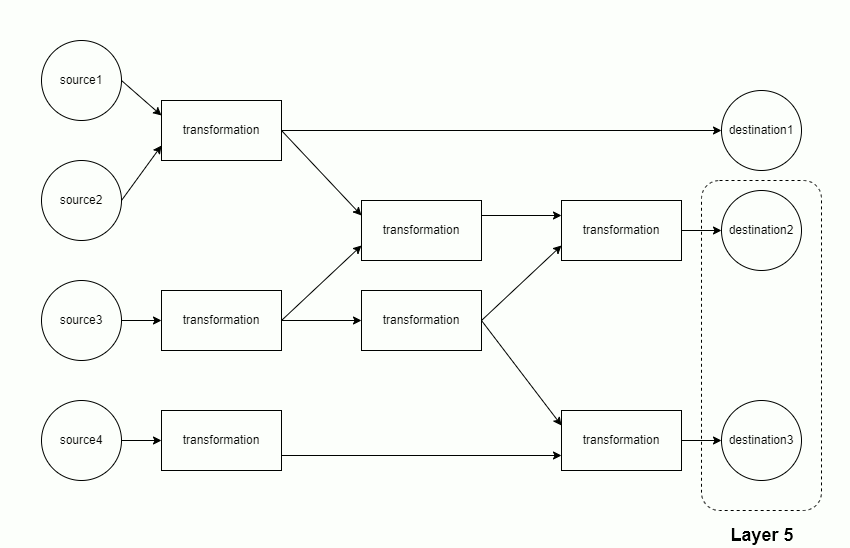
Tip: visualize an earthmover DAG
Setting config » show_graph: True will make earthmover run produce a visualization of the DAG for a project, such as
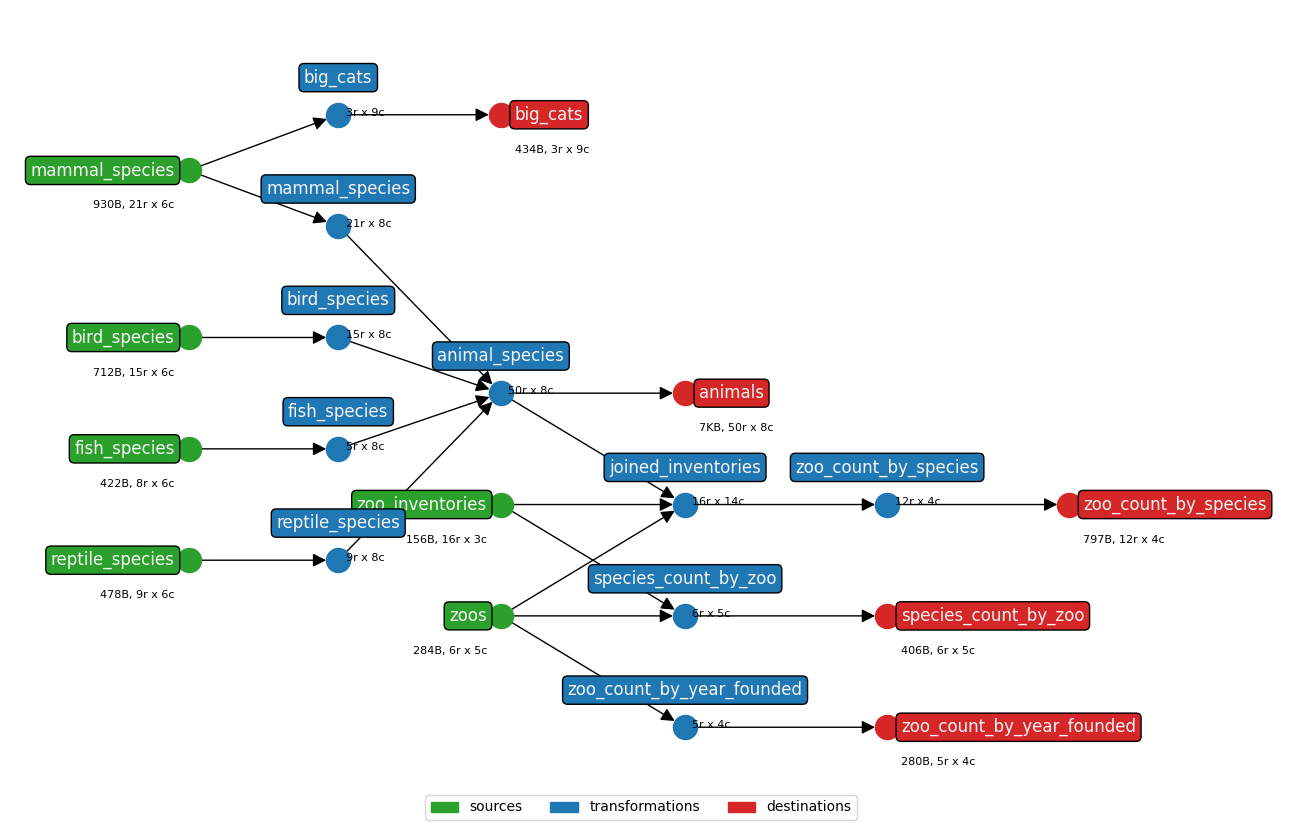
In this diagram:
- Green nodes on the left correspond to
sources - Blue nodes in the middle correspond to
transformations - Red nodes on the right correspond to
destinations sourcesanddestinationsare annotated with the file size (in Bytes)- all nodes are annotated with the number of rows and columns of data at that step
Dataframes
All data processing is done using Pandas Dataframes and Dask, with values stored as strings (or Categoricals, for memory efficiency in columns with few unique values). This choice of datatypes prevents issues arising from Pandas' datatype inference (like inferring numbers as dates), but does require casting string-representations of numeric values using Jinja when doing comparisons or computations.
Performance
Tool performance depends on a variety of factors including source file size and/or database performance, the system's storage performance (HDD vs. SSD), memory, and transformation complexity. But some effort has been made to engineer this tool for high throughput and to work in memory- and compute-constrained environments.
Smaller source data (which all fits into memory) processes very quickly. Larger chunked sources are necessarily slower. We have tested with sources files of 3.3GB, 100M rows (synthetic attendance data): creating 100M lines of JSONL (30GB) takes around 50 minutes on a modern laptop.
The state feature adds some overhead, as hashes of input data and JSON payloads must be computed and stored, but this can be disabled if desired.
Comparison to dbt
earthmover is similar in a number of ways to dbt. Some ways in which the tools are similar include...
- both are open-source data transformation tools
- both use YAML project configuration
- both manage data dependencies as a DAG
- both manage data transformation as code
- both support packages (reusable data transformation modules)
But there are some significant differences between the tools too, including...
earthmoverruns data transformations locally, whiledbtissues SQL transformation queries to a database engine for execution. (For databasesources,earthmoverdownloads the data from the database and processes it locally.)earthmover's data transformation instructions areoperationsexpressed as YAML, whiledbt's transformation instructions are (Jinja-templated) SQL queries.
The team that maintains earthmover also uses (and loves!) dbt. Our data engineers typically use dbt for large datasets (GB+) in a cloud database (like Snowflake) and earthmover for smaller datasets (< GB) in files (CSV, etc.).